Un runner de GitHub alimentado por energía solar
Cuanto más progresa nuestro pequeño proyecto, más código producimos. Y como la mayoría de nuestra comunidad hoy en día, alojamos nuestro código en GitHub.
Así que durante el desarrollo discutimos las implicaciones de una arquitectura DownToZero para algo como un proceso de GitHub. Rápidamente identificamos dos tipos de acciones que deben realizarse en la infraestructura.
La primera es la compilación CI, que siempre debe proporcionar retroalimentación inmediata al desarrollador. Comprueba el cumplimiento así como la integridad del código y suele estar profundamente implicada en el proceso de desarrollo. Estos trabajos son sensibles al tiempo porque alguien suele estar esperando por ellos.
La segunda categoría que identificamos es un poco diferente. Con el auge de dependabot y otros escáneres de seguridad, vimos cada vez más pipelines activados por estos bots. Lo que ocurre con eso es que queremos ejecutar el pipeline para comprobar nuestras dependencias y mantener nuestra base de código actualizada, pero al mismo tiempo, nadie está esperando esos pipelines. Así que no haría ninguna diferencia si esos pipelines se retrasaran.
Así que miremos la segunda categoría y veamos si podemos construir algo dentro de GitHub. Bueno, GitHub permite a cualquiera adjuntar runners autoalojados a cualquier proyecto (hosting your own runners). Si miras el proceso, es relativamente sencillo: descargar el runner, adjuntarlo a tu organización o repositorio y luego ejecutar el script de shell. También hay un pequeño ayudante que convierte este runner en un servicio systemd, así que no tenemos que iniciar y detener el servicio nosotros mismos.
Mirando la distribución de trabajos, GitHub dice que el trabajo en cola se mantiene durante 24 horas. Dentro de ese marco de tiempo el trabajo tiene que ser recogido o caducará. Entonces 24 horas es técnicamente suficiente tiempo para esperar a que salga el sol, independientemente de cuándo se haya generado el trabajo.
Con eso cubierto, empezamos a mirar nuestra configuración local y cómo podemos lograr dicha planificación de capacidad. Nuestra configuración actual se ve así.
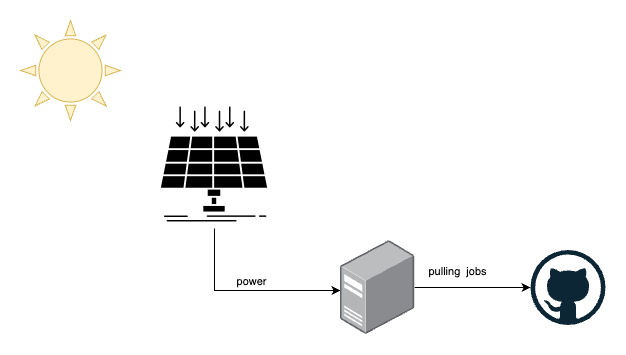
- tenemos paneles solares que producen energía
- tenemos máquinas locales que pueden consumir esa energía y tienen acceso a internet
- GitHub proporciona la cola de trabajos persistente para nuestro runner
No tenemos ningún almacenamiento de batería conectado, porque eso haría que todo el sistema fuera más caro y complejo.
Todas las métricas, como la producción de energía del panel solar o el consumo de energía de los servidores, se rastrean mediante dispositivos tasmota (CloudFree EU Smart Plug).
Así que conectamos todo. Para mayor comodidad, instalamos Ubuntu 22.10 (el mismo usado para el runner alojado por GitHub) en nuestras máquinas. También instalamos la cadena de herramientas que necesitábamos, como rustup, gcc-musl, protobuf.
Ahora, escribimos 3 servicios systemd independientes.
1) Servicio Dtz-Edge
El primer servicio está siempre en ejecución y lee la producción de energía desde HomeAssistant (aquí es donde se agregan nuestros datos de energía). También tiene en cuenta qué otros dispositivos están actualmente funcionando y cuánta energía ya están consumiendo. Luego implementa el siguiente modelo de estados:
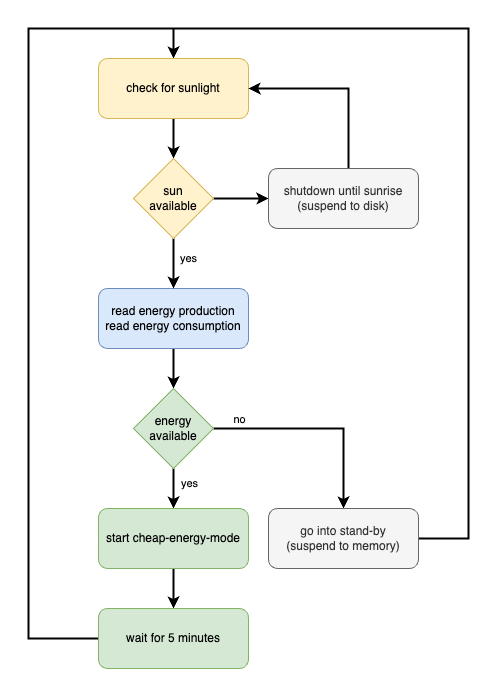
Definición de servicio systemd
[Unit]
Description=dtz edge Service
[Service]
Type=simple
WorkingDirectory=/root/dtz-edge
ExecStart=!/root/dtz-edge/busy.sh
Restart=always
[Install]
Alias=dtz-edge
WantedBy=multi-user.target
busy.sh shell script (versión abreviada)
#!/bin/bash
for (( ; ; ))
do
POWER=`curl -H 'Authorization: Bearer token1' -H "Content-Type: application/json" http://192.168.178.76:8123/api/states/sensor.solar_panel_energy_power 2> /dev/null | jq -r .state`
METER=`curl -H 'Authorization: Bearer token1' -H "Content-Type: application/json" http://192.168.178.76:8123/api/states/sensor.tasmota_energy_power_4 2> /dev/null | jq -r .state`
SALDO=$((POWER - METER))
echo "Saldo: $SALDO (solar: $POWER)"
CURRENT_HOUR=`date +%H`
if [ $CURRENT_HOUR -gt 17 ]; then
service cheap-energy stop
service actions.runner.DownToZero-Cloud.dtz-edge1 stop
echo "sleep till tomorrow (10h)"
rtcwake -m disk -s 36000
fi
if [ $SALDO -gt 70 ]; then
echo "more then 70: $SALDO"
service cheap-energy start
service actions.runner.DownToZero-Cloud.dtz-edge1 start
sleep 300;
else
service cheap-energy stop
rtcwake -m mem -s 660
fi
done
2) Servicio Cheap-Energy
Este servicio solo mantiene el estado de que hay energía barata disponible. Así que cuando este servicio systemd está en funcionamiento, significa que hay energía disponible; cuando se detiene, todos los workers deben apagarse. Por eso usamos este servicio como un proxy para facilitar la gestión.
[Unit]
Description=cheap energy
[Service]
Type=simple
WorkingDirectory=/root/dtz-edge
ExecStart=!/root/dtz-edge/cheap-energy.sh
Restart=always
[Install]
Alias=cheap-energy
WantedBy=multi-user.target
El script que ejecutamos aquí es solo un comando sleep.
#!/bin/bash
sleep infinity
3) Servicio GitHub Runner
Seguimos las instrucciones proporcionadas por GitHub e instalamos el runner como un servicio systemd.
sudo ./svc.sh install
Esto ya nos dio la definición de servicio correcta y lo único que necesitábamos cambiar fue la línea de dependencia del servicio. Porque ahora queremos que este servicio se ejecute siempre que el servicio cheap-energy esté en funcionamiento, y también que se detenga cuando cheap-energy se detenga.
Así que cambiamos nuestra definición de servicio (actions.runner.DownToZero-Cloud.dtz-edge1.service) para incluir la descripción BindsTo.
[Unit]
Description=GitHub Actions Runner (DownToZero-Cloud.dtz-edge1)
After=network.target
BindsTo=cheap-energy.service
[Service]
ExecStart=/home/user1/gh-dtz-org/runsvc.sh
User=user1
WorkingDirectory=/home/user1/gh-dtz-org
KillMode=process
KillSignal=SIGTERM
TimeoutStopSec=5min
[Install]
WantedBy=multi-user.target
Ahora que tenemos la parte de hardware de la solución configurada, volvamos al lado de GitHub.
Ahora tenemos 2 tipos de runners en nuestra UI de GitHub. Uno es el runner alojado por GitHub, en el que queremos que se ejecuten nuestras tareas de tipo 1, y otro es nuestro pool dtz-edge que solo se levanta cuando hay suficiente energía solar.
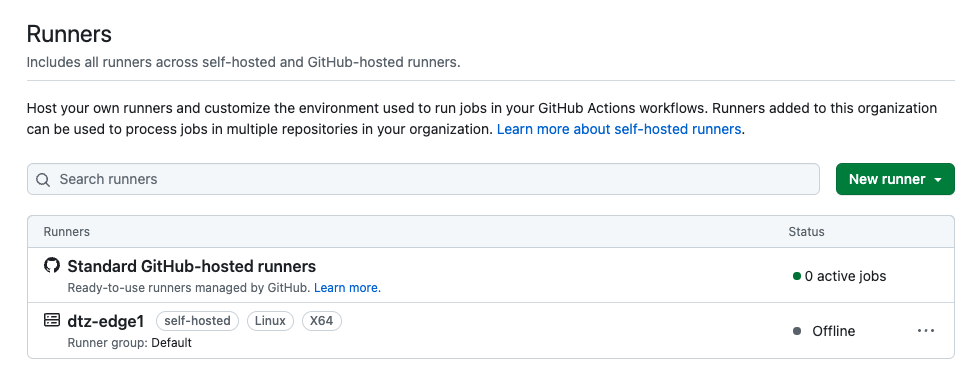
Dividamos nuestras definiciones de pipeline.
Para los trabajos de tipo 1, todo puede mantenerse como un pipeline normal de GitHub.
name: build
on:
workflow_dispatch:
push:
branches:
- main
jobs:
build:
permissions: write-all
runs-on: ubuntu-latest
Para los trabajos de tipo 2, es decir, los trabajos que queremos ejecutar con retraso en las máquinas alimentadas por energía solar, solo necesitamos definir la sección on-trigger para incluir los escenarios que deben ser soportados aquí. En nuestro caso empezamos haciendo esto para todos los pull requests. Luego, lo único que necesita cambiar es la declaración runs-on. Aquí colocamos nuestro runner recién generado.
name: pr
on:
workflow_dispatch:
pull_request:
jobs:
test:
name: coverage
runs-on: self-hosted
Así que ahora, siempre que dependabot nos envíe algunas actualizaciones para fusionar, o algún otro bot quiera comprobar tests y cobertura de código, esos trabajos se ejecutarán siempre que tengamos los recursos para hacerlo.
Como beneficio adicional, además ya no tenemos que pagar por estos runners extra. Los runners on-prem son gratuitos (en el sentido de la tarificación de GitHub).