A Solar Powered GitHub Runner
Plus notre petit projet progresse, plus nous produisons de code. Et comme la plupart des membres de notre communauté aujourd’hui, nous hébergeons notre code sur GitHub.
Donc, pendant le développement, nous avons discuté des implications d’une architecture DownToZero pour quelque chose comme un processus GitHub. Nous avons rapidement identifié deux types d’actions qui doivent être effectuées sur l’infrastructure.
La première est le build CI, qui doit toujours fournir un retour immédiat au développeur. Il vérifie la conformité ainsi que l’intégrité du code et est généralement profondément impliqué dans le processus de développement. Ces jobs sont sensibles au temps parce que quelqu’un attend généralement leur résultat.
La deuxième catégorie que nous avons identifiée est un peu différente. Avec la montée de dependabot et d’autres scanners de sécurité, nous avons constaté que de plus en plus de pipelines sont déclenchés par ces bots. Le problème est que nous voulons exécuter le pipeline pour vérifier nos dépendances et maintenir notre base de code à jour, mais en même temps, personne n’attend ces pipelines. Ainsi, cela ne ferait aucune différence si ces pipelines étaient retardés.
Jetons donc un coup d’œil à la deuxième catégorie et voyons si nous pouvons construire quelque chose au sein de GitHub. GitHub permet en effet à quiconque d’attacher des runners auto-hébergés à n’importe quel projet (hosting your own runners). Si vous regardez le processus, c’est relativement simple : télécharger le runner, l’attacher à votre organisation ou dépôt puis exécuter le script shell. Il y a aussi un petit utilitaire qui transforme ce runner en service systemd, de sorte que nous n’avons pas à démarrer et arrêter le service nous-mêmes.
En regardant la distribution des jobs, GitHub indique que le job en file d’attente est conservé pendant 24 heures. Dans ce laps de temps, le job doit être pris en charge sinon il expirera. Donc 24 heures sont techniquement suffisantes pour attendre que le soleil se lève, indépendamment du moment où le job a été lancé.
Une fois ceci couvert, nous avons commencé à regarder notre configuration locale et comment nous pouvons atteindre une telle planification de capacité. Notre configuration actuelle ressemble à ceci.
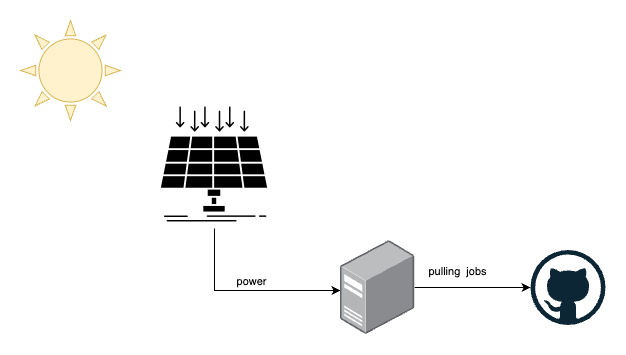
- nous avons des panneaux solaires qui produisent de l’énergie
- nous avons des machines locales qui peuvent consommer cette énergie et ont accès à Internet
- GitHub fournit la file d’attente persistante pour notre runner
Nous n’avons pas de stockage par batterie connecté, car cela rendrait le système entier plus coûteux et complexe.
Toutes les métriques, comme la production d’énergie du panneau solaire ou la consommation d’énergie des serveurs, sont suivies par des appareils tasmota indépendants (CloudFree EU Smart Plug).
Nous avons donc tout connecté. Par commodité, nous avons installé Ubuntu 22.10 (le même utilisé pour le runner hébergé par GitHub) sur nos machines. Nous avons également installé la chaîne d’outils dont nous avions besoin, comme rustup, gcc-musl, protobuf.
Maintenant, nous avons écrit 3 services systemd indépendants.
1) Service Dtz-Edge
Le premier service tourne en permanence et lit la production d’énergie depuis HomeAssistant (c’est là que nos données énergétiques sont agrégées). Il prend aussi en compte quels autres appareils sont actuellement en fonctionnement et combien d’énergie ils consomment déjà. Il implémente ensuite le modèle d’état suivant :
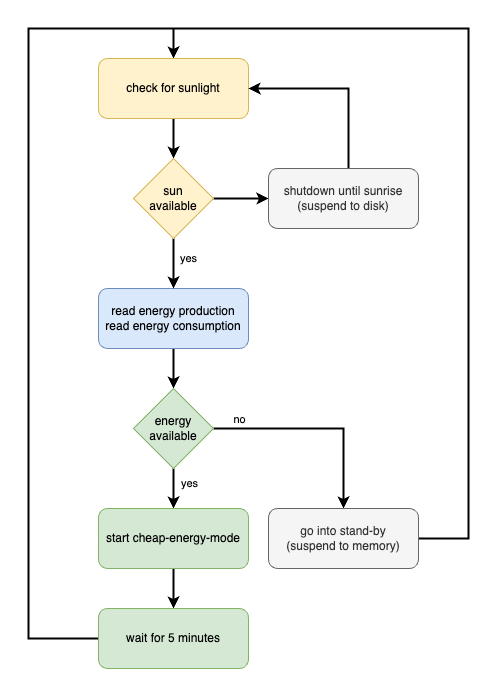
Systemd Service definition
[Unit]
Description=dtz edge Service
[Service]
Type=simple
WorkingDirectory=/root/dtz-edge
ExecStart=!/root/dtz-edge/busy.sh
Restart=always
[Install]
Alias=dtz-edge
WantedBy=multi-user.target
busy.sh shell script (shortened version)
#!/bin/bash
for (( ; ; ))
do
POWER=`curl -H 'Authorization: Bearer token1' -H "Content-Type: application/json" http://192.168.178.76:8123/api/states/sensor.solar_panel_energy_power 2> /dev/null | jq -r .state`
METER=`curl -H 'Authorization: Bearer token1' -H "Content-Type: application/json" http://192.168.178.76:8123/api/states/sensor.tasmota_energy_power_4 2> /dev/null | jq -r .state`
SALDO=$((POWER - METER))
echo "Saldo: $SALDO (solar: $POWER)"
CURRENT_HOUR=`date +%H`
if [ $CURRENT_HOUR -gt 17 ]; then
service cheap-energy stop
service actions.runner.DownToZero-Cloud.dtz-edge1 stop
echo "sleep till tomorrow (10h)"
rtcwake -m disk -s 36000
fi
if [ $SALDO -gt 70 ]; then
echo "more then 70: $SALDO"
service cheap-energy start
service actions.runner.DownToZero-Cloud.dtz-edge1 start
sleep 300;
else
service cheap-energy stop
rtcwake -m mem -s 660
fi
done
2) Service Cheap-Energy
Ce service ne détient que l’état indiquant qu’une énergie bon marché est disponible. Donc quand ce service systemd tourne, cela signifie qu’il y a de l’énergie disponible ; quand il est arrêté, tous les workers doivent s’arrêter. Nous utilisons donc ce service comme proxy pour faciliter la gestion.
[Unit]
Description=cheap energy
[Service]
Type=simple
WorkingDirectory=/root/dtz-edge
ExecStart=!/root/dtz-edge/cheap-energy.sh
Restart=always
[Install]
Alias=cheap-energy
WantedBy=multi-user.target
Le script que nous exécutons ici est simplement une commande sleep.
#!/bin/bash
sleep infinity
3) Service GitHub Runner
Nous avons suivi les instructions fournies par GitHub et installé le runner en tant que service systemd.
sudo ./svc.sh install
Cela nous a déjà donné la définition de service correcte et la seule chose que nous avons eu à changer était la ligne de dépendance du service. Parce que maintenant nous voulons que ce service s’exécute chaque fois que le service cheap-energy est en marche, et aussi qu’il s’arrête lorsque cheap-energy est arrêté.
Nous avons donc modifié la définition de notre service (actions.runner.DownToZero-Cloud.dtz-edge1.service) pour inclure la description BindsTo.
[Unit]
Description=GitHub Actions Runner (DownToZero-Cloud.dtz-edge1)
After=network.target
BindsTo=cheap-energy.service
[Service]
ExecStart=/home/user1/gh-dtz-org/runsvc.sh
User=user1
WorkingDirectory=/home/user1/gh-dtz-org
KillMode=process
KillSignal=SIGTERM
TimeoutStopSec=5min
[Install]
WantedBy=multi-user.target
Maintenant que nous avons la partie matérielle de la solution en place, revenons au côté GitHub.
Nous avons maintenant 2 types de runners dans notre interface GitHub. L’un est le runner hébergé par GitHub, sur lequel nous voulons que notre tâche de type 1 s’exécute, et l’autre est notre pool dtz-edge qui ne se lève que lorsqu’il y a suffisamment d’énergie solaire.
Détaillons nos définitions de pipeline.
Pour les jobs de type 1, tout peut rester comme dans un pipeline GitHub normal.
name: build
on:
workflow_dispatch:
push:
branches:
- main
jobs:
build:
permissions: write-all
runs-on: ubuntu-latest
Pour les jobs de type 2, donc les jobs que nous voulons exécuter avec retard sur les machines alimentées par le solaire, il suffit de définir la section de déclenchement on pour inclure les scénarios qui devraient être pris en charge ici. Dans notre cas, nous avons commencé par faire cela pour toutes les pull-requests. Ensuite, la seule chose qui doit être changée est l’instruction runs-on. Ici nous avons placé notre runner nouvellement créé.
name: pr
on:
workflow_dispatch:
pull_request:
jobs:
test:
name: coverage
runs-on: self-hosted
Ainsi, chaque fois que dependabot nous envoie des mises à jour à fusionner, ou qu’un autre bot veut vérifier les tests et la couverture du code, ces jobs s’exécuteront quand nous aurons les ressources pour le faire.
En bonus, nous n’avons plus à payer pour ces runners supplémentaires. Les runners on-prem sont gratuits (au sens de la tarification GitHub).