A Solar Powered GitHub Runner
Je weiter unser kleines Projekt voranschreitet, desto mehr Code produzieren wir. Und wie die meisten in unserer Community hosten wir unseren Code heutzutage auf GitHub.
Während der Entwicklung diskutierten wir die Implikationen einer DownToZero-Architektur für etwas wie einen GitHub-Prozess. Schnell identifizierten wir zwei Arten von Aktionen, die auf der Infrastruktur ausgeführt werden müssen.
Die erste ist der CI-Build, der dem Entwickler immer sofortiges Feedback liefern sollte. Er prüft die Konformität sowie die Integrität des Codes und ist normalerweise tief in den Entwicklungsprozess eingebunden. Diese Jobs sind zeitkritisch, weil in der Regel jemand auf deren Ergebnis wartet.
Die zweite von uns identifizierte Kategorie ist etwas anders. Mit dem Aufkommen von Dependabot und anderen Sicherheits-Scannern sahen wir immer mehr Pipelines, die von diesen Bots ausgelöst wurden. Das Besondere daran ist: Wir wollen die Pipeline laufen lassen, um unsere Abhängigkeiten zu prüfen und unseren Code aktuell zu halten, aber gleichzeitig wartet niemand auf diese Pipelines. Es würde also keinen Unterschied machen, wenn diese Pipelines verzögert ausgeführt würden.
Schauen wir uns also die zweite Kategorie an und prüfen, ob wir innerhalb von GitHub etwas aufbauen können. GitHub erlaubt es jedem, self-hosted Runner an ein Projekt anzuhängen (eigene Runner hosten). Wenn man sich den Prozess anschaut, ist er relativ einfach: den Runner herunterladen, an die Organisation oder das Repository anhängen und dann das Shell-Skript ausführen. Es gibt auch einen kleinen Helfer, der diesen Runner in einen systemd-Dienst verwandelt, sodass wir den Dienst nicht selbst starten und stoppen müssen.
Wenn man sich die Job-Verteilung anschaut, sagt GitHub, dass ein in die Warteschlange gestellter Job 24 Stunden gehalten wird. Innerhalb dieses Zeitrahmens muss der Job abgeholt werden, sonst läuft er ab. Technisch gesehen sind 24 Stunden also genug Zeit, um auf Sonnenaufgang zu warten, unabhängig davon, wann der Job gestartet wurde.
Nachdem das geklärt war, begannen wir, uns unser lokales Setup anzusehen und wie wir eine solche Kapazitätsplanung erreichen können. Unser aktuelles Setup sieht so aus.
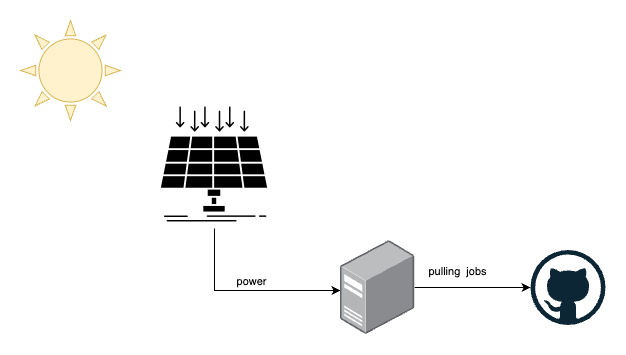
- wir haben Solarmodule, die Energie erzeugen
- wir haben lokale Maschinen, die diese Energie verbrauchen können und Internetzugang haben
- GitHub stellt die persistente Job-Warteschlange für unseren Runner bereit
Wir haben keinen Batteriespeicher angeschlossen, weil das das gesamte System teurer und komplexer machen würde.
Alle Metriken, wie die Energieausgabe des Solarpanels oder der Energieverbrauch der Server, werden von unabhängigen Tasmota-Geräten (CloudFree EU Smart Plug) erfasst.
Also haben wir alles angeschlossen. Bequemlichkeitshalber installierten wir auf unseren Maschinen Ubuntu 22.10 (dasselbe, das auch für den GitHub-gehosteten Runner verwendet wird). Wir installierten außerdem die benötigte Toolchain, wie rustup, gcc-musl, protobuf.
Nun schrieben wir 3 unabhängige systemd-Dienste.
1) Dtz-Edge Dienst
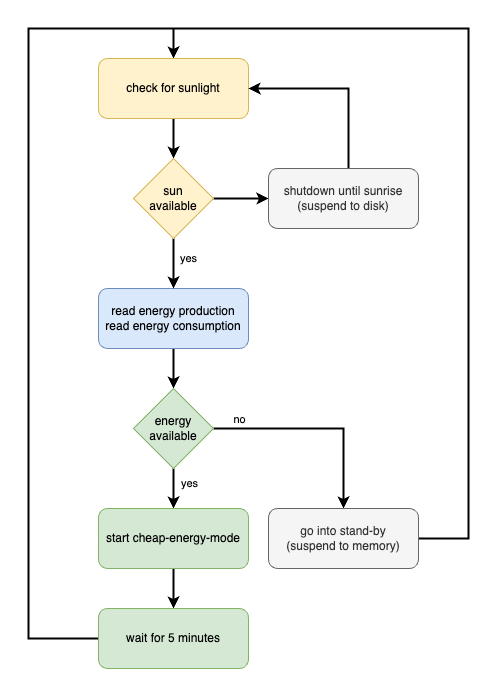
Der erste Dienst läuft immer und liest die Energieausgabe aus HomeAssistant (hier werden unsere Energiedaten aggregiert). Er berücksichtigt außerdem, welche anderen Geräte gerade laufen und wie viel Energie diese bereits verbrauchen. Anschließend implementiert er das folgende Zustandsmodell:
Systemd-Dienstdefinition
[Unit]
Description=dtz edge Service
[Service]
Type=simple
WorkingDirectory=/root/dtz-edge
ExecStart=!/root/dtz-edge/busy.sh
Restart=always
[Install]
Alias=dtz-edge
WantedBy=multi-user.target
busy.sh Shell-Skript (gekürzte Version)
#!/bin/bash
for (( ; ; ))
do
POWER=`curl -H 'Authorization: Bearer token1' -H "Content-Type: application/json" http://192.168.178.76:8123/api/states/sensor.solar_panel_energy_power 2> /dev/null | jq -r .state`
METER=`curl -H 'Authorization: Bearer token1' -H "Content-Type: application/json" http://192.168.178.76:8123/api/states/sensor.tasmota_energy_power_4 2> /dev/null | jq -r .state`
SALDO=$((POWER - METER))
echo "Saldo: $SALDO (solar: $POWER)"
CURRENT_HOUR=`date +%H`
if [ $CURRENT_HOUR -gt 17 ]; then
service cheap-energy stop
service actions.runner.DownToZero-Cloud.dtz-edge1 stop
echo "sleep till tomorrow (10h)"
rtcwake -m disk -s 36000
fi
if [ $SALDO -gt 70 ]; then
echo "more then 70: $SALDO"
service cheap-energy start
service actions.runner.DownToZero-Cloud.dtz-edge1 start
sleep 300;
else
service cheap-energy stop
rtcwake -m mem -s 660
fi
done
2) Cheap-Energy Dienst
Dieser Dienst hält nur den Zustand, dass günstige Energie verfügbar ist. Wenn dieser systemd-Dienst läuft, bedeutet das also, dass Energie verfügbar ist; wenn er gestoppt ist, sollten alle Worker heruntergefahren werden. Wir verwenden diesen Dienst also als Proxy, um das Management zu vereinfachen.
[Unit]
Description=cheap energy
[Service]
Type=simple
WorkingDirectory=/root/dtz-edge
ExecStart=!/root/dtz-edge/cheap-energy.sh
Restart=always
[Install]
Alias=cheap-energy
WantedBy=multi-user.target
Das Skript, das wir hier ausführen, ist einfach nur ein Sleep-Befehl.
#!/bin/bash
sleep infinity
3) GitHub-Runner-Dienst
Wir folgten den Anweisungen von GitHub und installierten den Runner als systemd-Dienst.
sudo ./svc.sh install
Das gab uns bereits die korrekte Dienstdefinition und das Einzige, was wir ändern mussten, war die Dienstabhängigkeitszeile. Denn jetzt soll dieser Dienst laufen, wann immer der cheap-energy-Dienst läuft, und außerdem soll dieser Dienst gestoppt werden, wenn der cheap-energy-Dienst gestoppt wird.
Also änderten wir unsere Dienstdefinition (actions.runner.DownToZero-Cloud.dtz-edge1.service), um die BindsTo-Beschreibung einzufügen.
[Unit]
Description=GitHub Actions Runner (DownToZero-Cloud.dtz-edge1)
After=network.target
BindsTo=cheap-energy.service
[Service]
ExecStart=/home/user1/gh-dtz-org/runsvc.sh
User=user1
WorkingDirectory=/home/user1/gh-dtz-org
KillMode=process
KillSignal=SIGTERM
TimeoutStopSec=5min
[Install]
WantedBy=multi-user.target
Jetzt, wo wir den Hardware-Teil der Lösung eingerichtet haben, kommen wir zurück zur GitHub-Seite.
Wir haben jetzt 2 Arten von Runnern in unserer GitHub-Oberfläche. Einer ist der von GitHub gehostete Runner, auf dem wir unsere Typ-1-Aufgaben ausführen möchten, und einer ist unser dtz-edge-Pool, der nur hochfährt, wenn genügend Solarstrom vorhanden ist.
Lassen Sie uns unsere Pipeline-Definitionen aufteilen.
Für die Typ-1-Jobs kann alles wie in einer normalen GitHub-Pipeline bleiben.
name: build
on:
workflow_dispatch:
push:
branches:
- main
jobs:
build:
permissions: write-all
runs-on: ubuntu-latest
Für die Typ-2-Jobs, also Jobs, die wir verzögert auf den solarbetriebenen Maschinen ausführen möchten, müssen wir lediglich den Abschnitt mit den on-Triggern so anpassen, dass die hier unterstützten Szenarien enthalten sind. In unserem Fall begannen wir damit, dies für alle Pull Requests zu tun. Dann muss nur noch die runs-on-Anweisung geändert werden. Hier haben wir unseren neu generierten Runner eingetragen.
name: pr
on:
workflow_dispatch:
pull_request:
jobs:
test:
name: coverage
runs-on: self-hosted
Wenn Dependabot uns nun also Updates schickt oder ein anderer Bot Tests und Code-Coverage prüfen möchte, werden diese Jobs ausgeführt, wann immer wir die Ressourcen dafür haben.
Als zusätzlicher Bonus müssen wir für diese zusätzlichen Runner nicht mehr bezahlen. On-Prem-Runner sind kostenfrei (im Sinne der GitHub-Preisgestaltung).